
首先让我们来回顾一下有关逻辑回归的知识。逻辑回归(Logistic Regression)虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression因其简单、可并行化、可解释强深受工业界喜爱。Logistic回归属于广义线性模型(generalizedlinear model)。这一类模型形式基本上都差不多,都具有wx+b的形式,其中w和b是待求参数。Logistic回归可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最常用的就是二分类的Logistic回归。
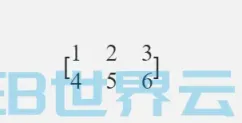
如下图所示,在逻辑回归的前向传播过程中,第一步我们要先计算出z,第二步计算出预测值y或a,最后计算出损失函数L。他们的计算公式之前已经讲过,这里就不再赘述了。(下图中假设只有两个特征1和2)

W上面的T表示矩阵转置。设W为m×n阶矩阵(即m行n列),第i行j列的元素是w(i,j),即:把m×n矩阵W的行换成同序数的列得到一个n×m矩阵,此矩阵叫做W的转置矩阵。
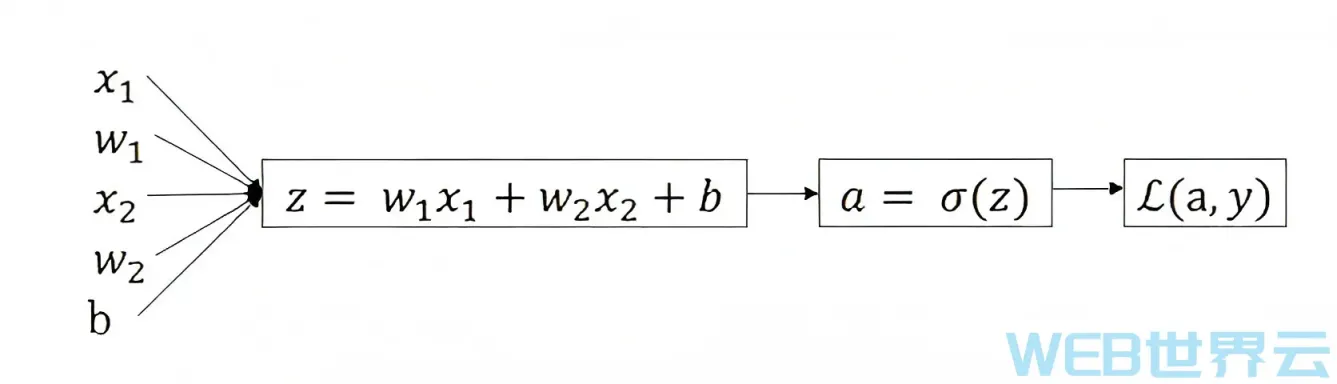
上面是前向传播,它对应的反向传播应该如何计算呢?
我们最终的且的是要计算出dL/dw1和dL/dw2以及dL/db,然后更新w1、w2、b以使损失函数L越来越小,使预测越来越精准。为了计算出dw1、dw2和db,第一步需要计算出da(dL/da,一般来说为了简便,会将dL省略掉。后面的dw、dz等等同理)。da的计算公式是-(y/a)+(1-y)/(1-a),这个公式是根据微积分知识求导出来的,如果你熟悉微积分你可以自己对L进行关于a的求导运算最终会得到上面的公式;如果你不熟悉微积分没有关系,只要记住上面那个公式就行了。
本系列教程中会提供所有相关的公式,从某些角度上来说,重点不在于那些公式,重点在于对人工智能机制和理论的理解以及如何利用人工智能技术解决实际问题。下一步我们需要求出dz,根据链式法则dz可以通过(dL/da)*(da/dz)求出,(dL/da)上面我们已经求出来了,(da/dz)的计算公式是a(1-a),经过计算后dz=a-y。同理,我们可以计算出dw1=x1dz,dw2=x2dz,db=dz。
上面这些公式都是针对于特定的函数来说的,因为在不同的神经网络中有各种不同的函数,例如损失函数就有Zero-one Loss(0-1损失),Perceptron Loss(感知损失),Hinge Loss,CrossEntropyLoss(交叉熵损失函数)等等,这些不同的函数构成了不同的前向传播,所以导致反向传播的求导也会不同。本篇文章中主要目的是让大家了解逻辑回归的偏导数的计算方式,不要太纠结公式细节。细节要根据不同项目背景进行不同的分析!
得到dw1、dw2、db后,就可以更新这些参数值进行梯度下降,例如W1=w1-r*dw1,(这里的r指学习率,不懂没事,后面课程会讲解的)然后用新的参数值再次进行前向传播然后再反向传播,通过这样不停的前向反向传播来训练参数。
上面我们使用”来表示学习率,后面还会使用不同的字母来表示学习率。由于字母就26个,在学科中经常会出现不够用的情况,所以也经常出现同一个字母表示不同含义的情况。所以大家要根据背景环境来判断某个字母当前表示什么含义!
上面讲述的是单个训练样本时如何计算逻辑回归的偏导数(训练样本一例如在训练识别猫的神经网络中,一张猫的图片就是一个训练样本),下面我给大家介绍多个训练样本时如何计算偏导数。
通过对前面文章的学习我们已经知道一一成本其实就是多个样本的损失的平均值一一m个样本的损失累加起来然后除以就是成本。同理,多个样本时的偏导数等于每个样本的偏导数的平均值。是的,就是这么简单!不要把事情想复杂了!世界本来就很简单!


评论留言