
传统编程的关注点是代码。而在机器学习项目中,很多时候我们需要将关注点移到“特征表示”上。也就是说,开发者通过添加和改善特征来调整模型使模式被训练得更好。
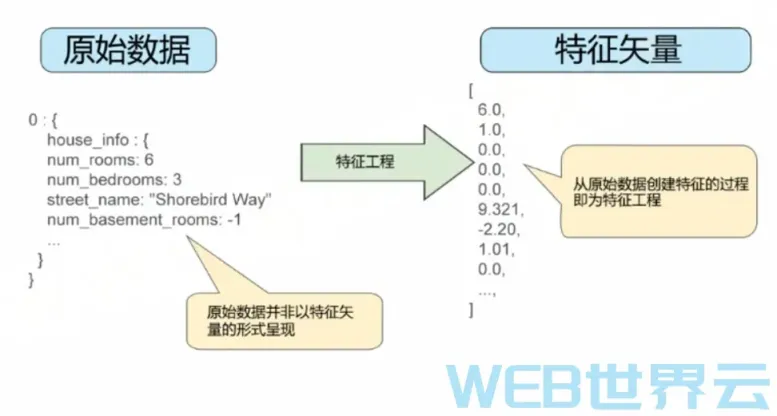
下图左侧表示原始数据,右侧表示对应的特征矢量(矢量是向量的别名)。特征工程指的是将原始数据转换为特征矢量。许多机器学习模型都必须将特征表示为实数向量,因为特征值要与模型权重相乘。
分类特征是指具有一组可能值的特征。例如,一个名为street_name的表示街道名称的分类特征,它的值就可能包括下面这些街道名:{‘Charleston Road’,’North ShorelineBoulevard’,’Shorebird Way’,’Rengstorff Avenue’}
由于模型不能将字符串与学习到的权重相乘,因此我们需要使用特征工程将字符串转换为数字值。要实现这一点,我们可以定义一个从特征值到整数的映射。世界上的每条街道并非都会出现在我们的数据集中,因此我们可以将那些没在数据库中的“其他街道”分组为一个“其他”类别,称为OOV。
我们可以按照以下方式将街道名称映射到数字:
将Charleston Road映射到 0
将North Shoreline Boulevard映射到 1
将Shorebird Way映射到 2
将Rengstorff Avenue映射到 3
将所有其他街道(OOV)映射到 4
不过,这种直接映射的方法有些漏洞。例如street_name可能有多个值。举个栗子,许多房屋位于两条街道的拐角处。为了避免直接映射的漏洞,我们可以为每个分类特征创建个二元向量,该向量的长度等于词汇表中的元素数。当向量中只有一个元素的值为1时,这种表示法称为独热编码;当有多个值为1时,这种表示法称为多热编码。
下图就是一个独热编码。在此二元矢量中,代表Shorebird Way的元素的值为1,而代表所有其他街道的元素的值为0。
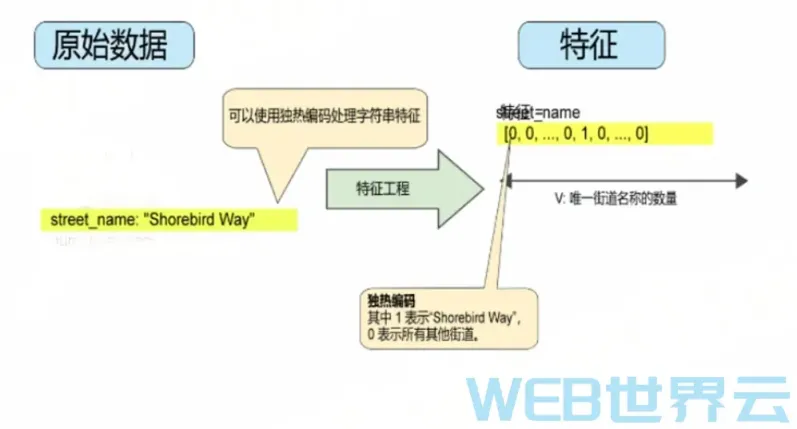
该方法能够有效地为每个特征值(例如,街道名称)创建布尔变量。采用这种方法时,如果房屋位于Shorebird Way街道上,则只有Shorebird Way的二元值为1。如果房屋位于两条街道的拐角处,则将两个二元值设为1。
假设数据集中有100万个不同的街道名称。如果直接创建一个包含100万个元素的二元向量,其中只有二或两个元素为ture(在编程中,true就表示1,false就表示O)则是一种非常低效的表示法,在处理这些向量时会占用大量的存储空间并耗费很长的计算时间。在这种情况下,一种常用的方法是使用稀疏表示法,其中仅存储非零值。
下面再给大家说说稀疏表示法相关的知识。
一个特征向量,其中的大多数值都为0或为空。例如,某个向量包含一个为1的值和一百万个为0的值,则该向量就属于稀疏向量,反之就是密集向量。
假设英语中包含一百万个单词。表示一个英语句子中所用单词的数量,有以下两种方式:
1、采用密集表示法来表示此句子,则必须为所有一百万个单元格设置一个整数,然后在大部分单元格中放入0,在少数单元格中放入一个非常小的整数。
2、采用稀疏表示法来表示此句子,则仅存储句子中实际存在的单词的单元格。因此,如果句子只包含20个独一无二的单词,那么该句子的稀疏表示法将仅在20个单元格中存储一个整数。
下面我们以上面两种方式来表示句子“Dogs wag tails.”。如下表所示,密集表示法将使用约一百万个单元格;稀疏表示法则只使用3个单元格:

向量或矩阵中设置为0(或空)的元素数量除以该向量或矩阵中的条目总数。以一个10×10矩阵(其中98个单元格都包含0)为例。稀疏性的计算方法如下:稀疏性稀疏性=98/100=0.98



评论留言