
大家已经学过如何将待预测数据输入到神经网络中,也明白了神经网络是如何对这些数据进行预测的,还知道了神经网络是如何判断自己预测得是否准确的。那么如果结果预测得不准确,是不是要想办法让预测
变得准确呢?这个努力让自己预测得更准确的过程就是学习。
在前面的文章中,我们已经知道,预测得是否准确是由W和b决定的,所以神经网络学习的目的就是要找到合适的w和b。通过一个叫做梯度下降(gradient descent)的算法可以达到这个目的。梯度下降算法会一步一步地改变W和b的值,新的W和b会使损失函数的输出结果更小,即一步一步让预测更加精准。

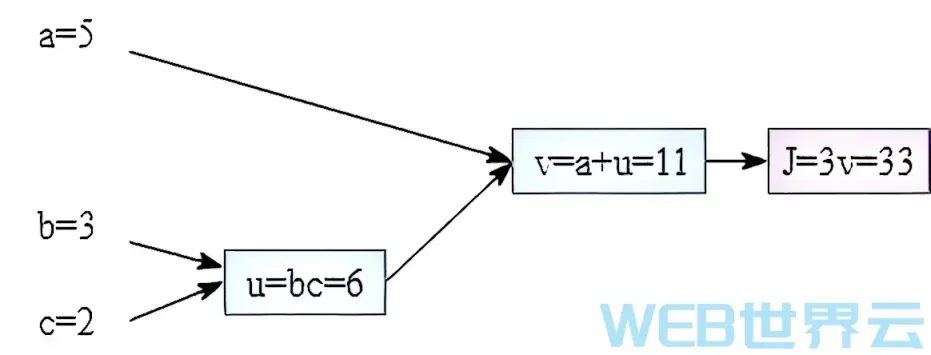
上面的公式是我们之前学到的逻辑回归算法(用于预测),以及损失函数(用于判断预测是否准确)。结合上面两个公式,输入x和实际结果y都是固定的,所以损失函数其实是一个关于w和b的函数(w和b是变量)。所谓“学习“或“训练神经网络”,就是找到一组w和b,使这个损失函数最小,即使预测结果更精准。
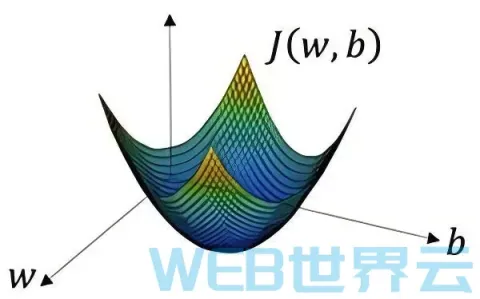
如上图所示,损失函数J的形状是一个漏斗状。我们训练的目的就是找到在漏斗底部的一组W和b。这种漏
斗状的函数被称为凸函数(向下凸起的函数)。我们选择J为损失函数的原因正是因为J是一个凸函数。
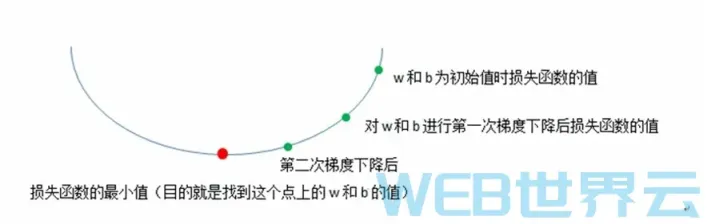
如上图所示,梯度下降算法会一步一步地更新W和b,使损失函数一步一步地变得更小,最终找到最小值或接近最小值的地方。
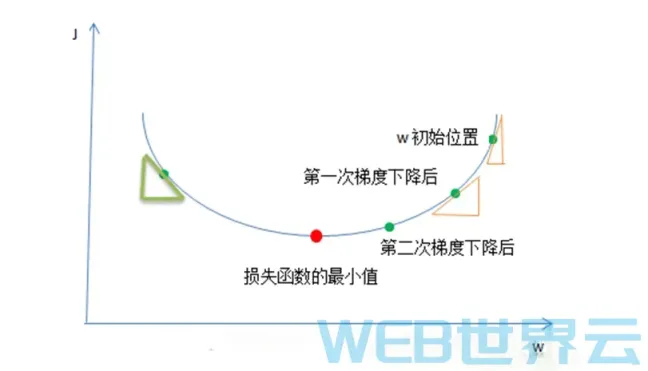
那么到底这个神秘的梯度下降算法是如何来更新W和b的呢?为了简化问题,让大家更容易理解其中的理论,我们先假设损失函数J只有一个参数w(实际上J是一个关于w和b的函数),并且假设W只是一个实数(实际上W是一个向量/一组实数)。如上图,梯度下降算法一步一步地在改变着W的值,在使损失函数的结果越来越小(将W的值一步一步的移到红点处)。我们是通过下面的公式来改变w的值的。
w` = w – r * dw
梯度下降算法就是重复的执行上面的公式来不停的更新W的值。新的w的值(W)等于旧的w减去学习率与导数dW的乘积。不要怕,我一步一步地给你解释它们。r表示学习步进/学习率(learning rate),假设w是10,又假设dw为1,”为4时,那么在第一次梯度下降后,w的值将变成6,而当”为2时,那么第一次下降后,w是8,从10变成了8比起从10变成6变化得没有那么大,因为变化率比较小。是我们用来控制W的变化步进的参数。dW是参数W关于损失函数J的偏导数,偏导数是数学微积分里面的一个概念,不懂不用怕,我会慢慢让你懂。偏导数说白了就是斜率。斜率就是变化比例,即当W改变一点点后J会相应的改变多少。看上图中的黄色的小三角,在W的初始值(假设为6)的位置的偏导数/斜率/变化比例就是小三角的高除以低边(J的变化除以w的变化),也就是在当W为6时J函数的变化与W的变化之比,曲线越陡,那么三角形越陡,那么斜率越大,那么当W的值改变一丁点后(例如减1)那么J相应的改变就会越大(假设会减小3),在下面那个小三角的位置(假设那里的w是4),这个位置的曲线不是那么的陡,即斜率比较小,那么在那里W的值改变一点后(例如也减小1)但J相应的改变却没有那么大了(可能只减小1.5)。这个斜率dw就是J的变化与w的变化的比例就是说,我们按照这个比例去使W越来越小那么它相应的J也会越来越小,最终达到我们的目的,找到J最小值时W的值是多少。
损失函数J的值越小,表示预测越精准。神经网络就是通过这种方法来进行学习的,通过梯度下降算法来一步一步改变W和b的值使损失函数越来越小,使预测越来越精准。其实原理还是很简单的!另外这里要说一下,W越来越小是一种相对的说法,例如看上面绿色的小三角的地方,这里的斜率是为负数的,所以W减去一个负数,等于w变大了,由于w/斜率/变化比例是负数,所以w变大,那么J就变小,最终还是会移到J的最小值处。
有人会说,那我每次都使w改变很多,那么就会更快的到达J的最小值处。是可以。但是,要控制好“度”,因为如果你每次让W改变太多,那么可能会错过了J的最小值处,例如上图中你可能会从w的初始位置直
接到了绿色小三角的位置(跳过了J的最小值处),之后你会左右来回跳,永远到不了J的最小值处。这就是”的用武之地,用它来控制W改变的步进,所以选择一个正确的学习率很重要。选错了,那么你的神经网络可能会永远找不到损失函数的最小值处,即你的神经网络预测得永远不会很准。后面后面的文章我会教大家如何来选择正确的学习率。面包会有的,牛奶也会有的!




评论留言